Learning-eBPF의 pdf에 기인한 내용(chapter4)이며 개인적으로 공부하며 작성되었기에 틀린 내용이 있다면 말씀해주시면 감사하겠습니다.

https://cilium.isovalent.com/hubfs/Learning-eBPF%20-%20Full%20book.pdf
본 chapter에서는 system call에 대해 다룬다.
우선적으로 ebpf() systemcall에 대해 살펴보자.
간만에 보는 반가운 녀석...(one-day분석때 징글징글하게 봄)
int bpf(int cmd, union bpf_attr *attr, unsigned int size);해당 함수는 ebpf map이나 program에 대한 명령을 수행하기 위한 친구이다.
- cmd: 말그대로 수행할 command
eBPF map과program을 조절하기 위한 많은 command들이 있다.
아래의 예시는 기본적으로 사용되는 load, create map, attach programs 등등이다.

attr: 말그대로 각종 속성들을 저장하는 곳인데 워낙 포함되는 데이터들이 많기에 kernel code를 통해 확인하는 것을 추천한다.
이제 본격적으로 bpf syscall을 파헤치기 위해 syscall을 tracing하는 strace를 활용하여 보자.
활용될 예시 프로그램은 아래와 같으며 이는 실행될때마다 perf buffer에 message를 보내고, execve() syscall event에 대한 정보를 userspace로 전달한다. chapter2인가...에서 있었던 프로그램과 유사하지만 각 사용자 ID에 대해 서로 다른 message를 구성할 수 있다는 차이점이 있다.
#!/usr/bin/python3
# -*- coding: utf-8 -*-
from bcc import BPF
import ctypes as ct
program = r"""
struct user_msg_t {
char message[12];
};
BPF_HASH(config, u32, struct user_msg_t);
BPF_PERF_OUTPUT(output);
struct data_t {
int pid;
int uid;
char command[16];
char message[12];
};
int hello(void *ctx) {
struct data_t data = {};
struct user_msg_t *p;
char message[12] = "Hello World";
data.pid = bpf_get_current_pid_tgid() >> 32;
data.uid = bpf_get_current_uid_gid() & 0xFFFFFFFF;
bpf_get_current_comm(&data.command, sizeof(data.command));
p = config.lookup(&data.uid);
if (p != 0) {
bpf_probe_read_kernel(&data.message, sizeof(data.message), p->message);
} else {
bpf_probe_read_kernel(&data.message, sizeof(data.message), message);
}
output.perf_submit(ctx, &data, sizeof(data));
return 0;
}
"""
b = BPF(text=program)
syscall = b.get_syscall_fnname("execve")
b.attach_kprobe(event=syscall, fn_name="hello")
b["config"][ct.c_int(0)] = ct.create_string_buffer(b"Hey root!")
b["config"][ct.c_int(501)] = ct.create_string_buffer(b"Hi user 501!")
def print_event(cpu, data, size):
data = b["output"].event(data)
print(f"{data.pid} {data.uid} {data.command.decode()} {data.message.decode()}")
b["output"].open_perf_buffer(print_event)
while True:
b.perf_buffer_poll()line 7~9: message출력할 배열 선언
line 11: data를 저장할 hash table map(type을 따로 지정하지 않을 시에 default는 u64)
line 32: helper function을 통해 userID를 받아온다. 매칭되는 userID에 따라 출력될 메세지를 결정한다.
상기의 코드를 실행해 보자.
sudo python3 ./hello-buffer-config.py
ls와 sudo ls 수행시의 output

이후에 strace로 확인
옵션 ref
https://itwiki.kr/w/%EB%A6%AC%EB%88%85%EC%8A%A4_strace
sudo strace -e bpf ./hello-buffer-config.pyoutput

상기의 output을 가지고 분석해보자.
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY, , key_size=4,
value_size=4, max_entries=4, ... map_name="output", ...}, 128) = 4출력에 사용될 perf buffer map을 생성
-map_type : PERF_EVENT_ARRAY
-name : output
-key / value size : 4
-return value(문장 상에서 제일 마지막에 있는 4) : 4(fd를 의미) -> userspace에서 output map에 access하기 위해 사용
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, value_size=12,
max_entries=10240... map_name="config", ...btf_fd=3,...}, 128) = 5
hash table map생성
key : 4byte -> u32type의 userID담김
value : 12byte -> msg_t의 크기(char[12])
btf_fd : 3 -> kernel에서 사용될 요소
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=44,
insns=0xffffa836abe8, license="GPL", ... prog_name="hello", ...
expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=3,...}, 128) = 6
prog_type : program type, kprobe에 연결
insn_cnt : instruction count, program의 bytecode 명령어 수
- 바이트코드 명령어는 insns 필드에 지정된 주소의 메모리에 보관
license = "GPL" : GPL-licensed BPF helper functions를 사용할 수 있도록 선언
program name : hello
expected_attatch_type : 해당 혜제에서는 일부 프로그램 유형에서만 활용(설명 미기재), 첫항목이기에 value는 0
prog_btf_fd : 3(fd)
만약 해당 프로그램이 verifier에 의해 거부된다면 -1의 value를 가지지만, value가 6이기에 적상적으로 통화되었음을 알 수 있으며 각 fd에 대한 정리는 아래와 같다.
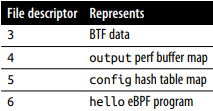
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=5, key=0xffffa7842490, value=0xffffa7a2b410,
flags=BPF_ANY}, 128) = 0
BPF_MAP_UPDATE_ELEM : map의 key-value쌍을 업데이트
BPF_ANY flag : map내에 key가 존재하지 않는 경우, 생성되어야함을 알리는 flag
map_fd : 어떤 map이 현재 사용되는지 식별
- 이때, key / value는 모두 pointer이므로, strace에 의해 수치화된 값이 나오는 것은 아니지만, bpftool을 활용하여 아래와 같이 요소들의 내용을 볼 수 있다.
#bpftool map dump name config output
[{
"key": 0,
"value": {
"message": "Hey root!"
}
},{
"key": 501,
"value": {
"message": "Hi user 501!"
}
}
]해당 요소들을 가져올 수 있는 이유는 BTF 정보 내에 정의된 것들을 사용하기 때문이다.
● BPF Program and Map References
- pinning
이미 chapter 3에서 나왔던 부분이다.
pinned object는 실제로 disk에 영구적으로 있는 파일이 아니다. 일반적인 file system과 같이 동작하는 pesudo filesystem으로써 존재한다. 그러나 메모리에 보관되기에 재부팅 시에 유지되지 않는다.
-about pseudo file system-
https://superuser.com/questions/1198292/what-is-a-pseudo-file-system-in-linux
pinning되지 않은 채로 ebpf program이 load되는 것을 허용한다면, bpftool이 종료될 때 fd가 해제되고 reference가 0이 될시에 program이 삭제될 것이다. 허나 pinng된 ebpf program의 경우 command가 수행된 이후에도 지속될 것이다.
reference counter는 trigger되는 hook이 연결될 때에도 증가한다. count는 eBPF program type에 의존적이며 tracing과 연관있고(chapter 7에서 다뤄질 예정) 항상 user space process와 연결된다. 이러한 경우, process가 종료되면 kernel의 참조 횟수가 감소한다.
netwrok stack이나 cgroup과 함께 부착된 program은 어떠한 user space process와 연관있지 않기에 load가 종료된 이후에도 유지된다. 이전에 봤던 XDP program에 대한 예시와 같다.
(아마 이전 챕터에서 실습 때, 따로 unload해주지 않으면 유지되어 있는 모습을 떠올리면 될 듯하다.)
ip link set dev eth0 xdp obj hello.bpf.o sec xdp
ip명령어가 수행된 이후 pinned location에 대한 정의가 없지만, bpftool은 XDP program이 kernel에 load된 상태를 보여준다.
$ bpftool prog list
…
1255: xdp name hello tag 9d0e949f89f1a82c gpl
loaded_at 2022-11-01T19:21:14+0000 uid 0
xlated 48B jited 108B memlock 4096B map_ids 612reference count는 0이 아니며, 이는 XDP hook이 ip link명령어가 수행된 이후에 지속적으로 부착되어 있기 때문이다.
eBPF map역시 reference count를 가지며 0이 될 시에 초기화 된다. map역시 사용하는 각 eBPF program의 counter를 증가시켜 user space의 program이 map을 가지고 있게 해준다.
map은 file system에 고정될 수도 있으며, user space program은 map 경로를 알면 map에 접근할 수 있다.
위와 같이 fd와 reference counter를 통해 참조하게 할 수도 있지만 다른 방법으로는 eBPF link도 있다.
● BPF link
BPF link는 eBPF program과 event같의 추상화된 layer를 제공한다. BPF link는 자체적으로 file system에 고정되어 program에 대해 추가적인 참조를 생성할 수 있다. 이는 kernel에 load한 user space process가 종료되어도 program이 load된 상태로 남아 있을 수 있다는 의미라고 한다.
user space loader program의 fd가 해제되어도 program에 대한 reference count는 감소하지만, BPF link에 의해 0이 되지는 않는다.
이후의 내용들은 너무 deep해서 현시점의 나에겐 이해하기에 너무 어려워 생략한다.
대략적으로 다루는 내용은 perf buffers, ring buffers, kprobes, and map iterations에 관련된 syscall에 대해 자세히 본다.
이상 chapter 4
'ebpf' 카테고리의 다른 글
| ebpf 공부용 링크들 다시 정리 (0) | 2024.06.19 |
|---|---|
| CO-RE, BTF, and Libbpf (0) | 2024.02.11 |
| Anatomy of an eBPF Program (0) | 2024.01.24 |
| eBPF programming (0) | 2024.01.09 |
| Troubleshooting - learning eBPF (0) | 2024.01.01 |